I went to bed. 53 minutes later, I had a working NFL game prediction microservice. Here’s how the Ralph Wiggum paradigm turned a concept document into a deployed application with machine learning predictions for this weekend’s Conference Championship games.
What is the Ralph Wiggum Paradigm?
The Ralph Wiggum technique, created by Geoffrey Huntley, is an AI-assisted development approach that runs a coding agent from a clean slate, over and over, until a stop condition is met. As Matt Pocock describes it: “an AI coding approach that lets you run seriously long-running AI agents (hours, days) that ship code while you sleep.”
The key insight is preventing context rot. Instead of having an LLM accumulate confusion over a long session, each iteration starts fresh with a clear PRD (Product Requirements Document). The agent implements one feature, verifies it works, commits, and the next iteration picks up where the last left off.
I’ve packaged this into ralph-cli-sandboxed, a CLI that automates the entire workflow inside a Docker sandbox.
The Starting Point: A Concept Document
Everything began with Markus Eisele’s tutorial about building an NFL game predictor with Java, Quarkus, and Tribuo. Instead of following the tutorial step-by-step, I asked Claude to create a concept document that captured the architecture, components, and implementation approach.
The concept markdown covered:
- Tech stack: Java 21, Quarkus, Tribuo ML, PostgreSQL, ESPN API
- Architecture diagram showing data flow from ESPN through feature engineering to predictions
- Project structure with all packages and classes
- Entity definitions for Team and Game
- ML pipeline components: TrainingExample, FeatureBuilder, ModelTrainer, ModelInference
- REST endpoints and Qute templates
- Configuration requirements
This concept document became the foundation for everything that followed.
From Concept to PRD: The Generator
My ralph-cli-sandboxed project includes a PRD-GENERATOR.md file that takes a concept document and transforms it into a structured PRD. The generator creates granular, verifiable tasks that an AI agent can execute independently.
I also fed it a FEEDBACK.md file from a previous build attempt where I created the project “just” with Claude Code which needed some adjustments. This is where the Ralph approach shines: failed builds aren’t wasted. They generate feedback that improves the next iteration’s PRD.
The resulting prd.json contained 25 tasks organized by category:
[
{
"category": "setup",
"description": "Generate Quarkus project with required extensions",
"steps": [
"Run: mvn io.quarkus.platform:quarkus-maven-plugin:create ...",
"Add extensions: quarkus ext add hibernate-orm-panache rest-client ...",
"Note: jdbc-h2 enables Docker-free dev mode with in-memory database",
"Verify project structure exists with src/main/java and pom.xml",
"Run ./mvnw compile to verify setup succeeds"
],
"passes": false
},
// ... 24 more tasks
]
Each task has:
- A category (setup, config, feature, integration, bugfix)
- A clear description
- Granular steps with verification commands
- A passes flag that tracks completion
The PRD included hard-won knowledge from the feedback file:
- Use
PanacheEntityBaseinstead ofPanacheEntityfor explicit ID control - Import
SimpleDataSourceProvenancefromorg.tribuo.provenance, notorg.tribuo.datasource - ESPN ID for the Dolphins is 15, not 20 (data integrity matters)
- Use
ListDataSource<Label>to wrap examples for Tribuo 4.3.2 API compatibility
These details would have cost me some time to vibe code the fixes. Instead, they were encoded into the PRD from the start.
Running Ralph Overnight
With the PRD ready, I kicked off the build:
ralph docker run
Ralph runs inside a Docker container with network sandboxing (only GitHub, npm, and Anthropic API allowed). The container mounts my ~/.claude credentials and passes as parameter --dangerously-skip-permissions to enable autonomous operation (YOLO mode).
Started Ralph:
ralph run
… and then I went to bed.
53 Minutes Later
When I checked the logs the next morning, Ralph had completed all 25 tasks. The git history showed a clean progression:
- Project scaffolding with Quarkus
- Tribuo dependencies added
- Application configuration for H2 dev mode and ESPN API
- Team and Game entities with computed statistics
- ESPN API DTOs and REST client
- Data ingestion service with team and game loading
- Feature engineering pipeline
- Model training with logistic regression
- Model inference for predictions
- Admin REST endpoints
- Qute UI for displaying predictions
- Startup service for automatic data loading
- Sample data in import.sql
Each commit represented a verified feature: the check commands passed, tests ran, the application compiled.
Note:: these tests were written by the same LLM, so take the “verified” with a grain of salt. For a more detailed discussion on the testing paradox in AI-assisted development, see my series The T in vibe coding stands for testing.
The Two Bugs
All 25 tasks passed. Ralph marked everything complete, the check commands succeeded, the application compiled and started. But when I manually tested the running application, I found two issues that the automated verification hadn’t caught.
This highlights a gap in the PRD: the tasks verified that code compiled and tests passed, but didn’t include explicit “hit this endpoint and verify it returns valid data” checks. Lesson learned for next time: add integration verification steps like “curl /upcoming-games and confirm HTML response” or “call /api/admin/refresh-games and verify JSON structure.”
The fix was straightforward: add bugfix tasks to the PRD and let Ralph handle them.
Bug 1: Template rendering error
The /upcoming-games endpoint showed:
io.quarkus.qute.runtime.TemplateProducer$InjectableTemplate$InjectableTemplateInstanceImpl@37c63651
Instead of rendering the template, the resource was returning the TemplateInstance object directly.
Bug 2: Jackson deserialization failure
The /api/admin/refresh-games endpoint threw:
com.fasterxml.jackson.databind.exc.MismatchedInputException:
Cannot deserialize value of type `java.lang.String` from Object value
The ESPN API response structure had nested objects where the DTO expected strings.
I added both bugs to the PRD:
{
"category": "bugfix",
"description": "upcoming-games endpoint show error",
"steps": [
"open /upcoming-games",
"shows error: io.quarkus.qute.runtime...",
"verify that app is shown"
],
"passes": false
},
{
"category": "bugfix",
"description": "/api/admin/refresh-games causes a stacktrace",
"steps": [
"Call /api/admin/refresh-games endpoint",
"which causes @stacktrace.txt",
"fix",
"verify endpoint is responding correct content"
],
"passes": false
}
Ran Ralph again. Both bugs fixed. Total additional time: about 6 minutes.
The Result: Conference Championship Predictions
With the application running, I synced real NFL data from ESPN and trained the model on the 2025-2026 season. The predictor now shows upcoming games with ML-powered win probabilities.
For this weekend’s Conference Championship games the model predicts Denver over New England with 100% confidence (the 10-7 vs 4-13 records make that an easy call) and Seattle at home over the equally-matched Rams at 94%. Note: looking at the Patriots numbers seems they are from last season - don’t blame me!
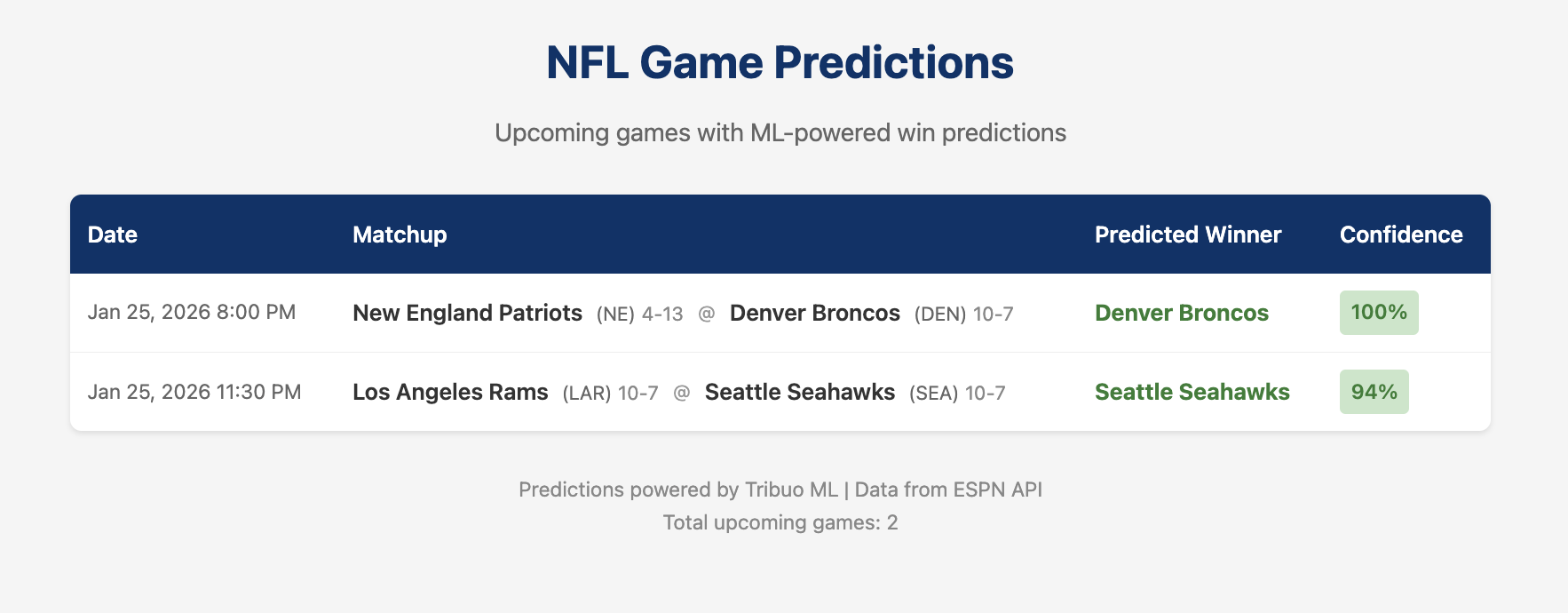
The model uses team statistics (win percentage, average points scored/allowed) and home field advantage to predict outcomes. It’s a simple logistic regression classifier, but the architecture supports swapping in XGBoost or other algorithms.
Why This Works
The Ralph paradigm succeeds because it addresses the core limitations of AI-assisted development:
Context rot prevention: Each iteration starts fresh. No accumulated confusion from long conversations.
Verifiable progress: Every task includes verification steps. The agent can’t mark something complete without proving it works.
Failure as feedback: Failed attempts generate insights that improve the next PRD. Nothing is wasted.
Autonomous execution: Running in a sandboxed container with appropriate permissions lets the agent work without interruption.
Human oversight at the right level: I define what to build (the concept and PRD). The agent figures out how to build it. When it fails, I diagnose and update the PRD.
The Workflow
For anyone wanting to replicate this approach:
-
Create a concept document: Capture architecture, components, and implementation details. This is your north star.
-
Generate the PRD: Transform the concept into granular, verifiable tasks. Take a look at my
PRD-GENERATOR.mdfile and also include lessons learned from any previous attempts. -
Run Ralph: Start the sandbox environment
ralph docker run, start Ralphralph runand walk away. Let the agent work through the PRD. -
Review and iterate: Check the results. Add bugfix tasks for anything that failed. Run again.
-
Ship it: When all tasks pass, you have a working application.
-
DON’T SHIP IT: It’s a trap! The Ralph Wiggum paradigm doesn’t mean your application is safe to ship. The code hasn’t been security reviewed, the tests only check what the same LLM thought to check, edge cases are likely missing, and dependencies haven’t been audited. Ralph gets you to a working prototype fast. Human review, proper testing, and security hardening still need to happen before production.
What’s Next
The NFL predictor is functional but basic. Potential enhancements encoded in the concept document:
- Weather conditions and injury reports as features
- Stadium-specific home advantage (Denver altitude, dome vs outdoor)
- XGBoost instead of logistic regression
- Model accuracy tracking over time
- Kafka for live game updates
- GraalVM native compilation
Each of these could be a new PRD. The pattern scales.
Summary
- 53 minutes of compute time and two bug fixes produced a working ML microservice that predicts NFL games.
- The Ralph Wiggum paradigm prevents context rot by starting each iteration fresh with a clear PRD.
- Every task includes verification steps so the agent can’t mark something complete without proving it works.
- Failed attempts generate insights that improve the next PRD, so nothing is wasted.
- Running in a sandboxed container with appropriate permissions enables autonomous operation.
- The key is investing time in the concept and PRD: clear requirements, granular tasks, and verification steps.
- Ralph gets you to a working prototype fast, but human review, proper testing, and security hardening still need to happen before production.
References:
- Ralph Wiggum technique: ghuntley.com/ralph
- ralph-cli-sandboxed tool: GitHub
- NFL Game Prediction tutorial by Markus Eisele: the-main-thread.com
- Quarkus framework: quarkus.io
- Tribuo ML library: tribuo.org
{kind=link}